SOLUTION BRIEF
Thinking About Disaster Recovery In The Cloud? Don't Forget The Network!
Disaster recovery(DR) is an integral part of an organization’s business continuity plans and for those with applications in the cloud, implementing an effective DR strategy is critical, especially for the overall risk management of the organization.
When some organizations have thought about DR, they mainly focus on ensuring their corporate data is secure and replicated across regions in the cloud and that it meets certain compliance regulations. However, when the network that enables users to gain access to that data fails or doesn’t perform properly, it impacts the overall operations of the organization.
The right way to think about this is to decouple the application from network infrastructure and also focus on building a highly available and fault-tolerant cloud networking transit. To get started, it’s important to consider some items;
Many cloud network solutions claim to be cloud-native but are designed using traditional data center technologies with virtual appliances.
Some cloud network solutions are delivered as-a-service ( mid-mile offering ) that is suited for small-scale deployments. Medium to large enterprises need control over their data and how the DR requirements are implemented as the network scales or complexity grows
A true cloud-native network solution is built using modern application architectures and can dynamically and cost-effectively meet network scaling requirements. Even more important, they allow enterprises to have full control to ensure they can maintain data sovereignty and the network can meet its DR needs.
Cloud transit’s fault-tolerance
The cloud network solution should be able to handle disruptions in the cloud seamlessly. From flapping network links to outages in cloud regions, the cloud network transit should always be available to deliver traffic to the application regardless of its location
Consistent user experience
Application locations will change in the cloud following the execution of a DR plan and the cloud network should be able to deliver a consistent user experience regardless of disruptions within the network or where the application is located.
A transit that can understand the usage patterns of applications, the layer the application is connected to the transit ( L3, L4, or L7 ), and the impact of any failure to each of the applications, be it a partial or complete outage of any service in the path. The insights about the application help it build layers of fault tolerance.
Let’s explore how Prosimo’s autonomous cloud network platform helps organizations build a highly available and fault-tolerant network that meets the requirements above. The platform uses a combination of proactive monitoring through heartbeat messages and DNS programming and we discuss them in detail below.
Scenario
Acme, Inc deployed a business-critical application, app.acme.com, in instances in the US-West region. As part of their DR plan, another set of instances running the same application has been deployed in the US-East region. Employees who access this application are based in the Philippines. Also, this application is accessed by other applications, app2.acme.com and app3.acme.com, which fetch data used for analytics within Acme. Acme deployed the Prosimo cloud network platform within their cloud environment using the architecture below.
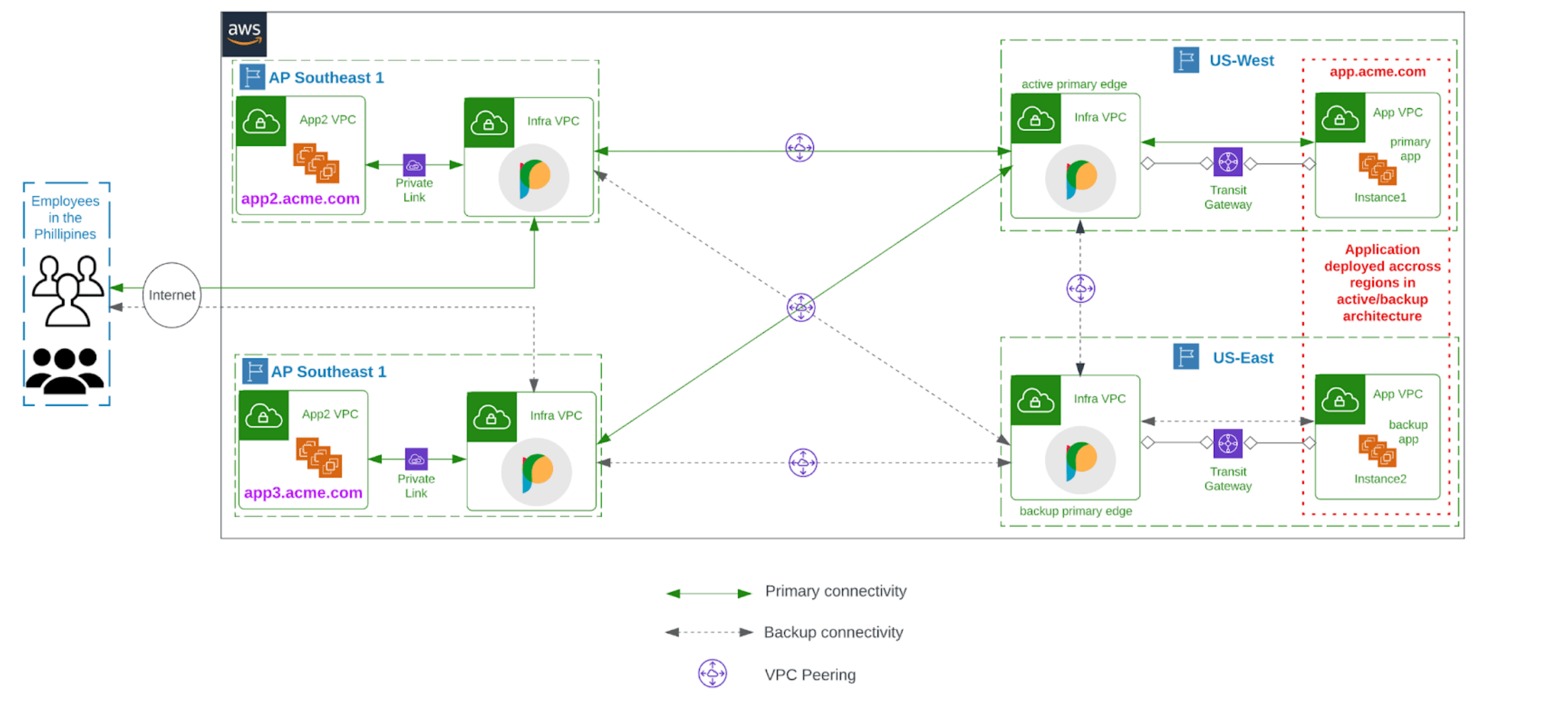
- The application is deployed in instances across AWS US-West and US-East regions.
- Instances in the US-West region serve as the primary application endpoint while US-East serves as the backup.
- Prosimo edge gateways have also been deployed in AWS US-West and US-East regions and connect to instances deployed in the respective regions through an AWS Transit Gateway(TGW).
- The edge gateways are also deployed as active and backup primary edges in US-West and US-East regions respectively.
- The edge gateways establish cross-regional cloud-native peering to connect US regions. Acme leverages this connectivity to replicate data across the instances.
- Acme also deployed 2 Prosimo edge gateways in the AWS AP-Southeast region to provide quick access to the cloud network for their employees.
- Both edge gateways are deployed in AP-Southeast-1 and AP-Southeast-3 regions respectively
- Prosimo edge gateways create fabric by establishing cloud-native peering over the AWS backbone
- Primary edges are configured with information on how to reach instances deployed in their respective regions.
- Secondary edges are configured with information on how to reach primary edges.
- Prosimo edges contain reverse-proxy capabilities, sitting in the data path between user and applications.
Prosimo’s autonomous cloud-network platform addresses Acme’s DR needs within the network in 2 ways;
- Edge gateway resiliency
- Platform resiliency
The edge gateways serve as gatekeepers and sit in the path between the employees and applications. It’s of critical importance that these gateways meet Acme’s fault-tolerance requirements as any failures within any single gateway can potentially render the application unavailable. Prosimo edge gateways are always deployed in multiple availability zones such that if one zone becomes unavailable, the other is available to handle the application traffic.
Prosimo built the edge gateway using a cloud-native design; running a cluster of microservices within Kubernetes and it Inherits a lot of the failover mechanisms inherent within. Within each edge gateway, multiple worker nodes simultaneously handle application traffic and they are managed and constantly monitored by a master node. If one worker node fails, traffic is re-routed to other worker nodes while another node is instantiated to replace the one that failed. Also, because traffic spikes could occur occasionally, additional worker nodes are automatically instantiated to accommodate this change in the traffic pattern.
Each worker node contains several pods which provide security, optimization, visibility, and other services. Live monitoring of these pods occurs within the worker node to detect and quickly recover from any faults that may occur.
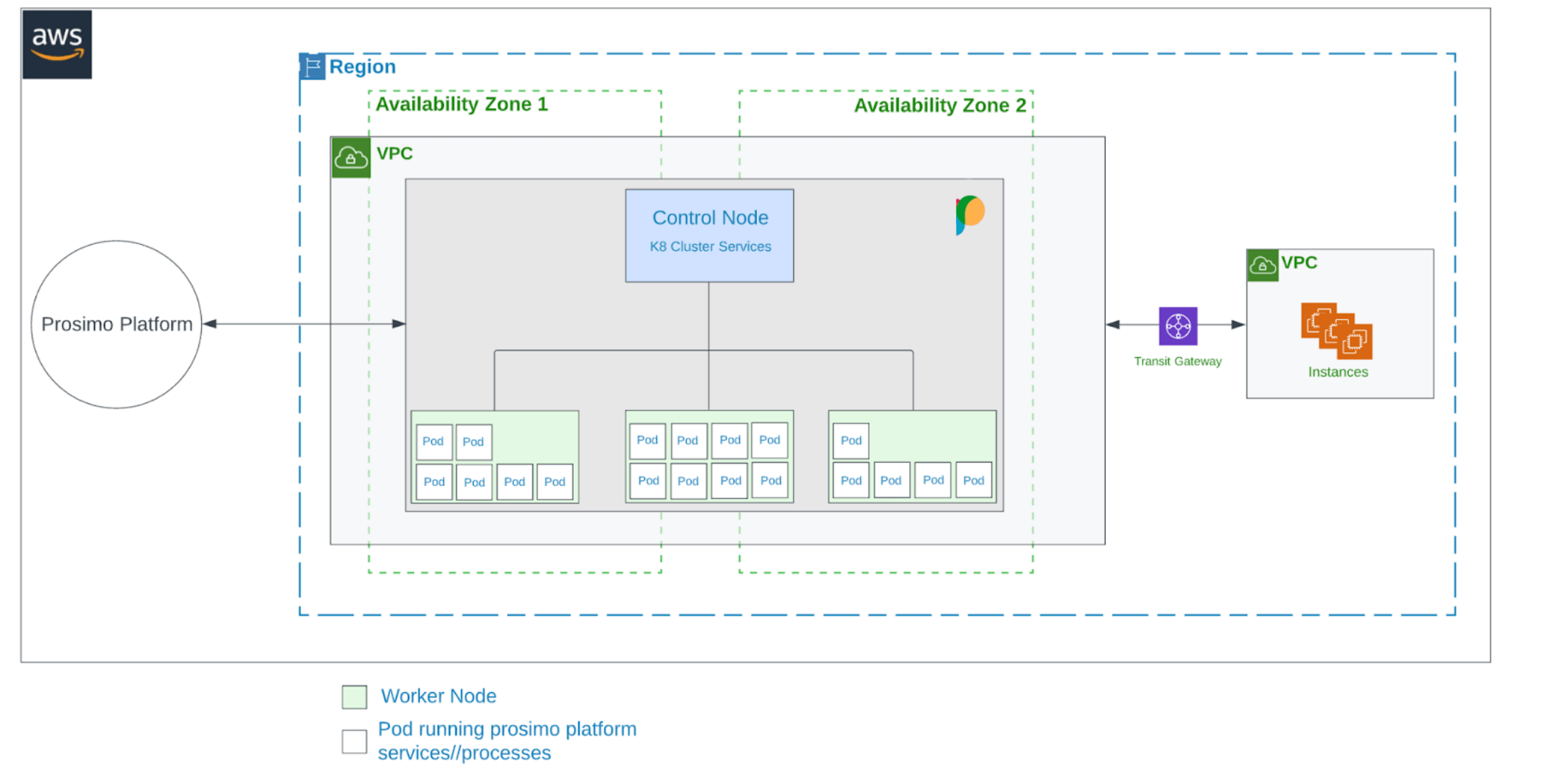
With this multi-layered fault-tolerant design, Prosimo edge gateways not only ensure access to Acme’s application is always available but also quickly recover from any internal disruptions that may occur.
Platform resiliency
The platform actively uses heartbeat messages, DNS, and software-defined networking concepts to maintain a resilient cloud network for organizations. Heartbeat messages are used throughout the fabric to continuously monitor the edges and applications. A centralized controller exchanges heartbeat messages with the edges and the edges exchange heartbeat messages between themselves to proactively detect and workaround failures. Edge gateways deployed on the platform are assigned unique hostnames and the platform updates DNS with this information which is used by edges to communicate with other edges as well as by users to communicate with the platform. These updates allow for a seamless redirection of traffic to alternate paths when failover is required.
As the application is critical to the business, Acme requires a network that can work around any unplanned disruptions to ensure their employees in the Philippines always have access. Prosimo addresses this requirement in 2 ways
- Application failover
- Edge network failover
Application failover
As mentioned earlier, Acme deployed the application in instances across US-West and US-East Regions with the instances in the US-West region serving as the active application while the US-East instance serves as a backup. Prosimo edge gateways have been deployed in both regions where instances are located. The controller configures the active primary edge with details of the backup primary edge. It uses this information to determine where to redirect active traffic when failover is required.
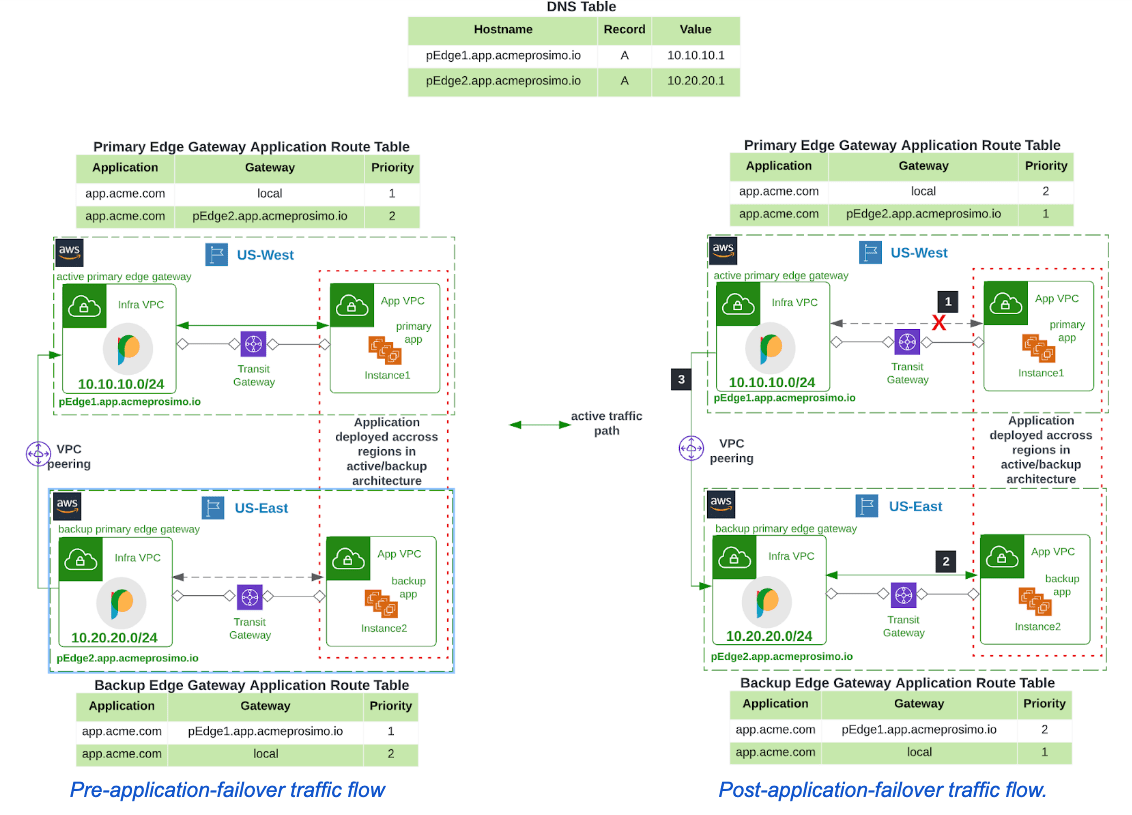
The steps below describe how failover occurs:
- Failover to the backup application begins after the active application is marked as unresponsive as a result of not responding to successive heartbeat messages from the active primary edge gateway.
- The backup primary edge gateway will also begin allowing traffic flow to the backup application.
- The active primary edge gateway will forward live traffic to the backup primary edge at 10.20.20.1.
- It will determine the hostname of the backup primary edge(pEdge2.acme.prosimoedge.io) from its route table and determine the IP address using DNS. This is done prior to failover occurring so the switch occurs quicker.
The application will now be reachable in the US-East region through the backup primary edge.
If Acme had users in the US-West region, they would have connected to the application through the active primary edge in that region. When the failover occurs, the active primary edge will forward traffic from users in that region to the backup application through the backup primary edge in the US-East region.
Edge network failover
As shown earlier, Acme deployed additional Prosimo Ingress edges(also termed secondary edges) in AP-Southeast-1 and AP-Southeast-3 regions which extend the platform to the regions close to the employees in the Philippines. Acme uses these edge gateways to provide a consistent and optimized user experience at all layers of the networking stack(i.e. using cloud backbone, TCP optimization, caching, and others.) and also function as ingress points for securely connecting users to the application.
Edge network failover in Acme’s network is addressed in two scenarios;
- Between secondary and active/backup primary edge gateways.
- Between employees and secondary edge gateways.
Between secondary and active/backup primary edge gateway
The secondary edge gateways also exchange heartbeat messages with primary edges. When the primary edge gateways detect the application instance is unavailable, they signal failover execution to the secondary edges using the heartbeat messages. A similar signal is seen when the primary edge gateway is unavailable which could happen when there’s an outage in the cloud region.
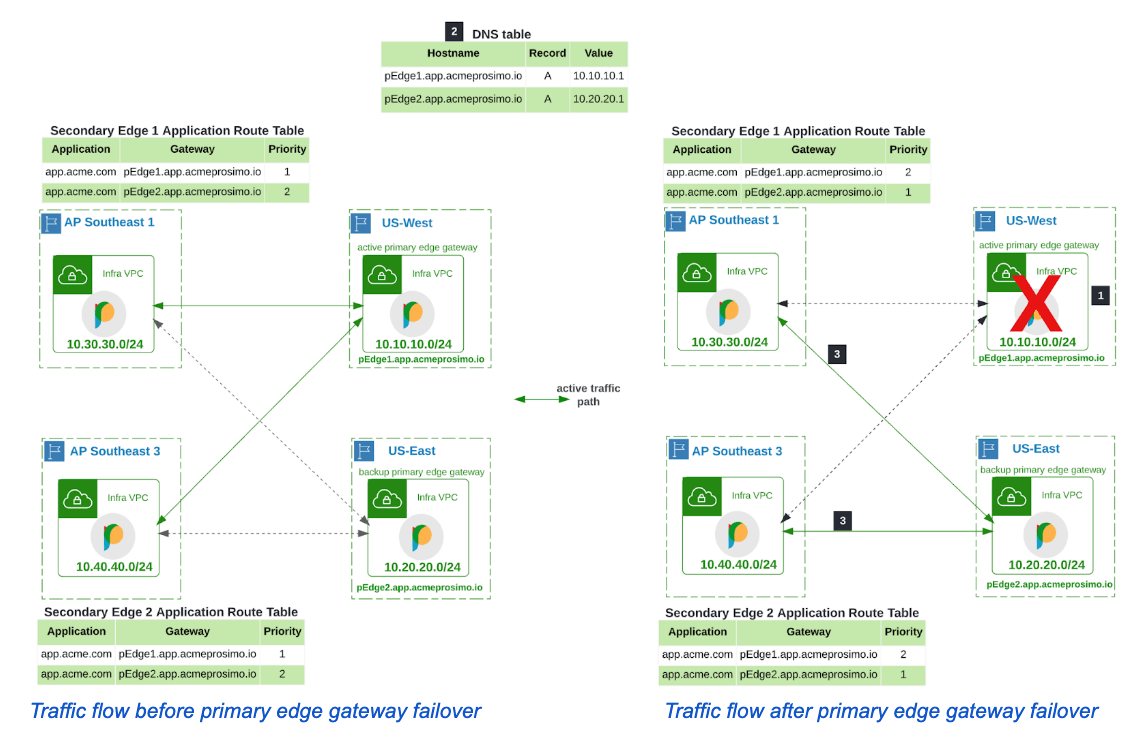
In Acme’s network, The platform controller programs the secondary edge gateways with information about the active and backup primary edge gateway for the application. Both secondary edges failover to the backup primary edge in similar fashion.
- They mark the active primary edge at IP 10.10.10.1, as unresponsive after successive missed heartbeat messages.
- They query DNS for the IP address of the backup edge gateway
- They lookup the backup primary edge gateway details in their application route table I.e. pEdge2.app.acmeprosimo.io and query DNS for this hostname
- They forward traffic to the backup edge at IP 10.20.20.1.
As the backup primary edge gateways also mark the active primary edge as unresponsive, it would have begun allowing traffic to flow to the backup instances of the application.
Between source endpoints and ingress edges
As mentioned previously, Prosimo’s edge gateways contain reverse-proxy capabilities which allow them to receive and forward traffic on behalf of users and applications. The platform uses simple DNS configurations to insert itself in the path for authentication/authorization of users and proxied access to applications. DNS is also used to quickly redirect user traffic to an alternate edge gateway when a failover is required.
In Acme’s network, and applications in the AP-Southeast region, app2.acme.com, and app3.acme.com access the business-critical application through the secondary edge gateways sEdge1 and sEdge2. Both applications perform similar functions for Acme and if an unplanned disruption occurs within the AP-Southeast-1 region or with gateway sEdge1, app3.acme.com will continue to fetch data from app.acme.com through gateway sEgde2.
The employees in the Philippines access the application through the secondary edge gateway(sEdge1) deployed in the AP-Southeast-1 region. The application hostname, app.acme.com, has been CNAMEd to Prosimo and is reachable through the IP address of sEdge1, 200.198.196.194.
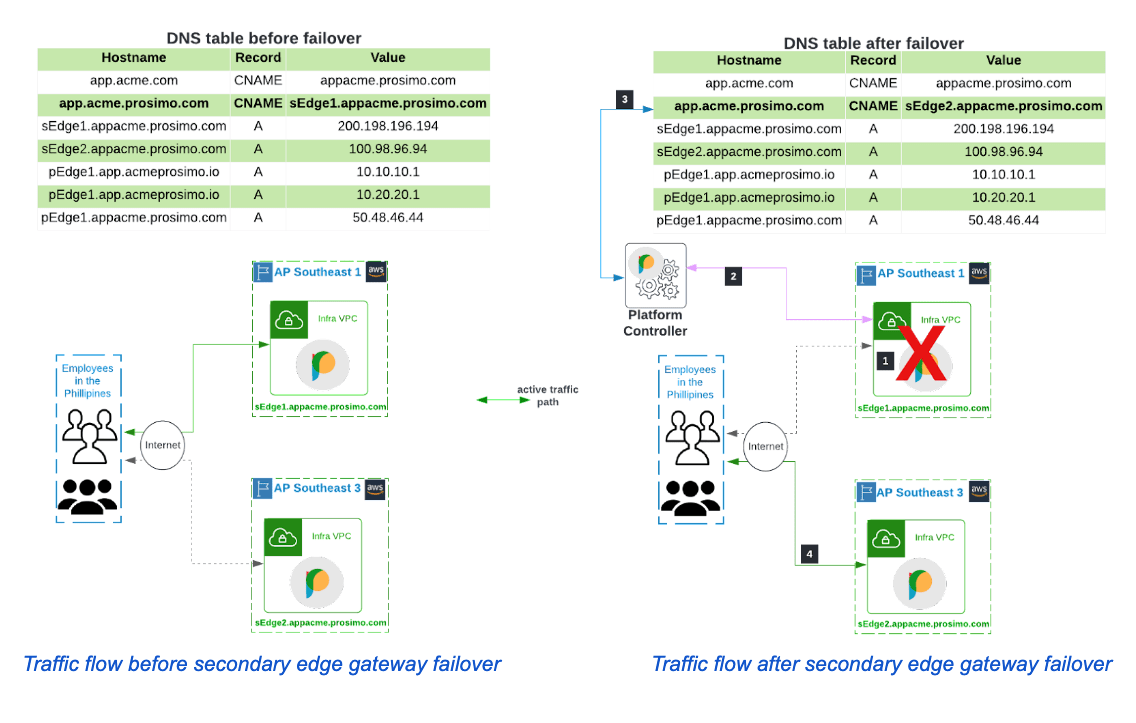
Where an unplanned disruption occurs, causing the edge gateway in the AP-Southeast-3 region(sEdge1) to become unavailable, the below steps describe how the platform quickly detects the disruption and seamlessly redirects the employee traffic to the edge gateway in AP-Southeast-3, sEdge2
- The secondary edge gateway in the AP-Southeast-1 region, sEdge1, becomes unavailable following an unplanned disruption in the cloud region.
- The platform controller marks sEdge1 as unresponsive.
- Heartbeat messages are exchanged regularly between the edge gateway and the controller to determine the gateway’s availability and as a result of the outage in the region, the controller received no responses to successive heartbeat messages that were sent.
- The controller modifies the DNS table to ensure the redirection of traffic to sEdge2.
- The application CNAME entry is modified to the hostname of the edge gateway deployed in the AP-Southeast-3 region, i.e. sEdge2.appacme.prosimo.com.
- Employee traffic for application, app.acme.com is forwarded to sEdge2.
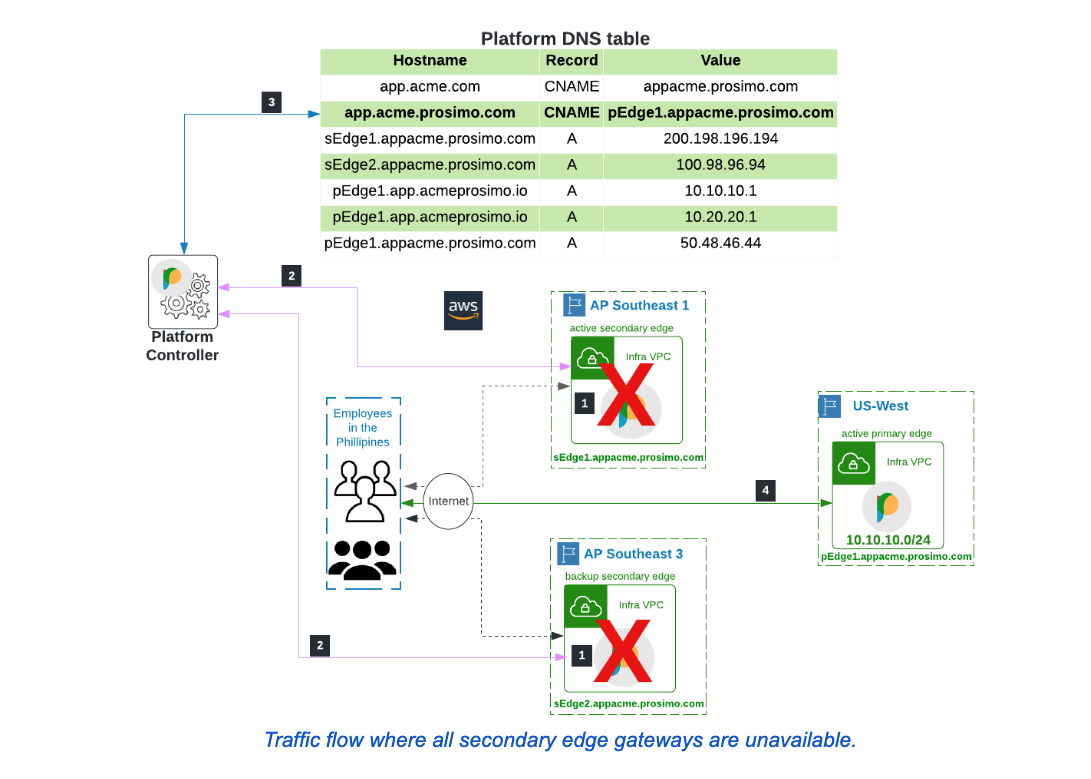
In the unlikely event that no secondary edge gateway is available in Acme’s network, the platform controller will redirect traffic to the primary edge gateway of the application. The procedure is similar to the process described above. The only change is in step 3, where the CNAME entry is modified to the hostname of the primary edge gateway deployed in the US-West region.
In summary
Using the Prosimo platform, Acme can build a highly available and fault-tolerant cloud network architecture that will meet their DR expectations and mitigate the impact on business operations. Proactive monitoring at multiple areas and seamless traffic redirection using DNS ensure the application is always accessible through the network as users’ experience remains consistent.
Reach out to us at Prosimo to learn more about building your cloud network that meets your disaster recovery needs.